들어가며
인터넷은 단일한 공간이 아닌 여러 층의 구조를 지닌다. 우리가 평소 사용하는 구글 검색 결과나 일반 웹사이트는 전체 웹의 일부분일 뿐이며, 그 이면에는 검색 엔진에 노출되지 않는 Deep Web, 익명성과 암호화를 기반으로 운영되는 Dark Web 영역이 존재한다.
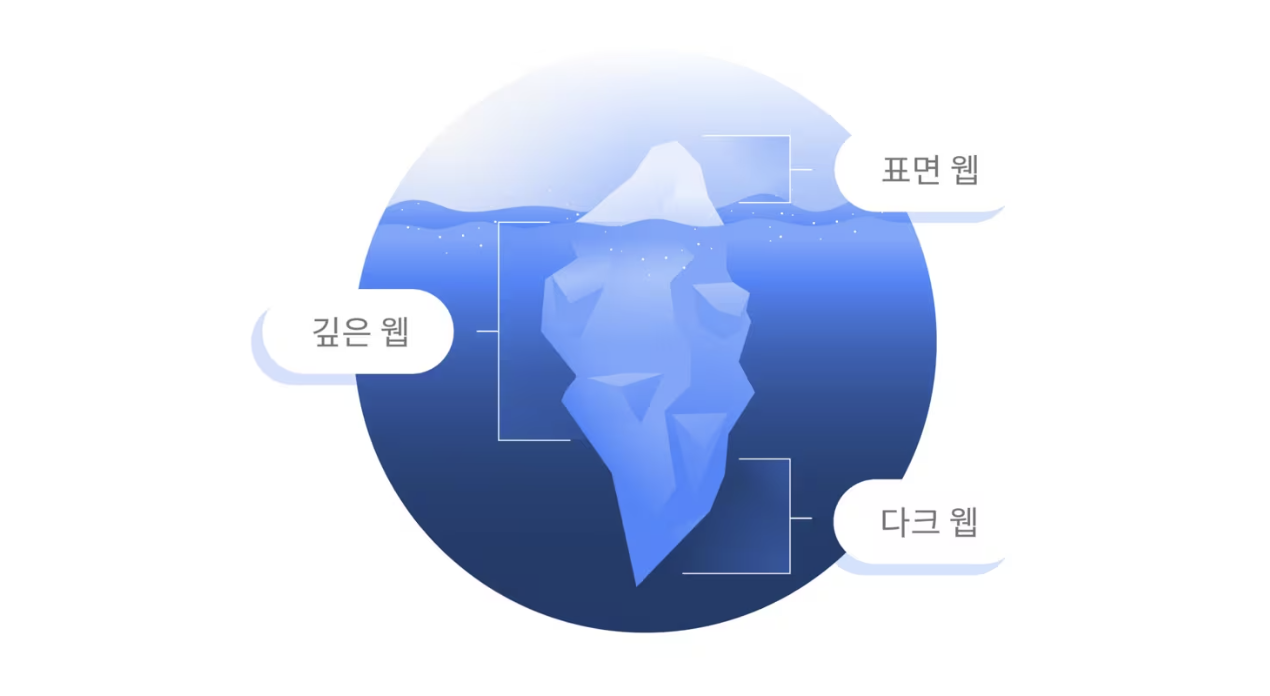
최근 프로젝트의 일환으로 다크웹에 접근하는 기본적인 방법을 알아보고 법적 허용 범위 내에서 크롤링을 시도해보았다.
Tor browser
다크웹은 Chrome, Firefox와 같은 일반 브라우저로는 접근할 수 없으며, 특수한 네트워크를 통해서만 연결된다. 가장 대표적인 방법이 Tor(The Onion Router) 브라우저를 이용한 접속이다.
설치
Tor 브라우저는 사용자의 IP 주소와 트래픽 경로를 여러 노드를 통해 우회함으로써 익명성을 보장해주는 브라우저이다.
설치는 official website를 통해 다운로드 가능하며, 설치 이후에는 일반 브라우저와 유사한 UI로 .onion 도메인에 접근할 수 있다.
예시: http://exampleonionaddress.onion/
처음 실행 시 ‘Tor 네트워크 연결’을 확인한 뒤 시작한다.
.onion 도메인은 일반 검색엔진에 나타나지 않으며, 커뮤니티 기반의 디렉터리를 통해 탐색할 수 있다.
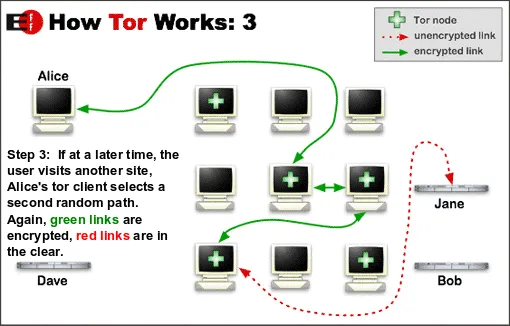
단점은 매우 느리다. 여러 국가의 네트워크를 경유하여 가기 때문이다. 예를 들어, ‘개인 PC(한국) > 루마니아(경유) > 러시아(경유) > 네덜란드(경유) > 인터넷’ 과 같은 방식이다. 최종 인터넷 단계에서는 ‘네덜란드 접속’으로 보이며, 이를 역추적하려면 다시 위 국가들을 거쳐야 한다.
Tor 브라우저에서는 패킷을 양파 껍질처럼 겹겹이 암호화하여 보내고, 이때 각각의 노드의 공개키를 통해 암호화하므로, 패킷의 출발지와 목적지를 알아내려면 거의 모든 노드를 장악해야 한다.
Security Requirements
다크웹 접속은 기술적으로 익명성을 제공하지만, 사용자의 실수나 미흡한 설정으로 인해 위험에 노출될 수 있다. 다음의 보안 수칙은 Tor 브라우저 탐색을 위해 필수로 준수해야 할 사항들이다.
- VPN 병행 사용: Tor 이전에 VPN을 실행하여 트래픽을 이중 암호화.
- JavaScript 비활성화: Tor 설정에서 JavaScript를 꺼야 추적 위험 감소.
- 개인정보 입력 금지: 실명, email, 전화번호, etc.
- 파일 다운로드 주의:
.zip,.pdf등 악성코드 포함 가능성.
크롤링 시도
다크웹의 구조적 특성과 익명성을 이해하기 위해 웹 크롤링을 몇 가지 시도해보았다. 합법적인 공개된 .onion 사이트 대상이다.
다크웹 사이트는 대부분 리소스가 매우 제한적인 서버에서 운영되며, 트래픽이 급증하면 운영자 입장에서 DDoS 공격으로 오해할 수 있다. 따라서 크롤링을 통한 일정량 이상의 요청 감지로 자동 접속 차단, Tor 회선 차단 등의 대응을 한다.
크롤링이 굉장히 까다롭다는 의미인데, 기존에 공개된 Darkweb Crawler 몇 가지를 추려 실험해보았다.
FreshOnions
requirements.txt
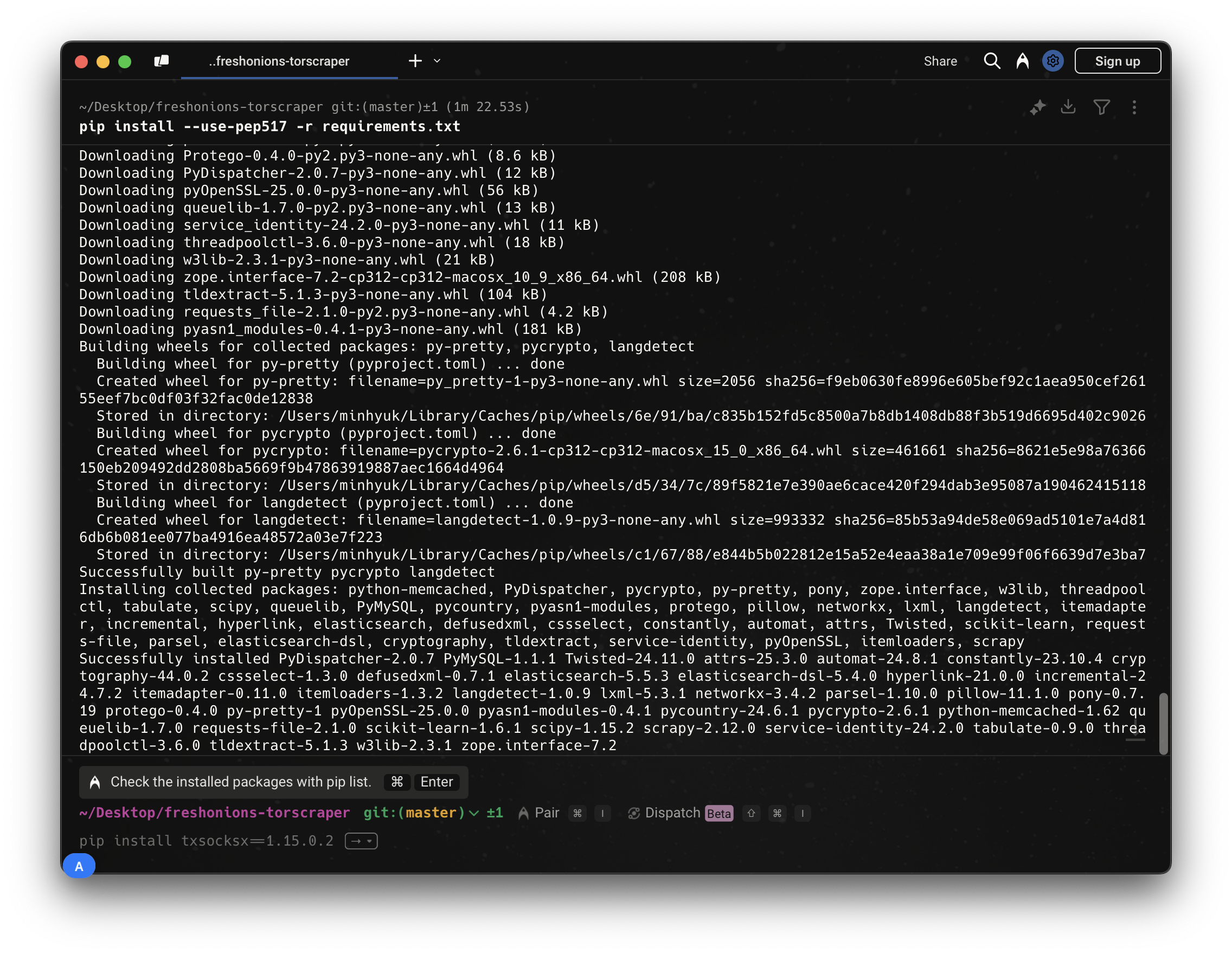
가장 먼저, requirements.txt 설치 중 오류가 발생했다.
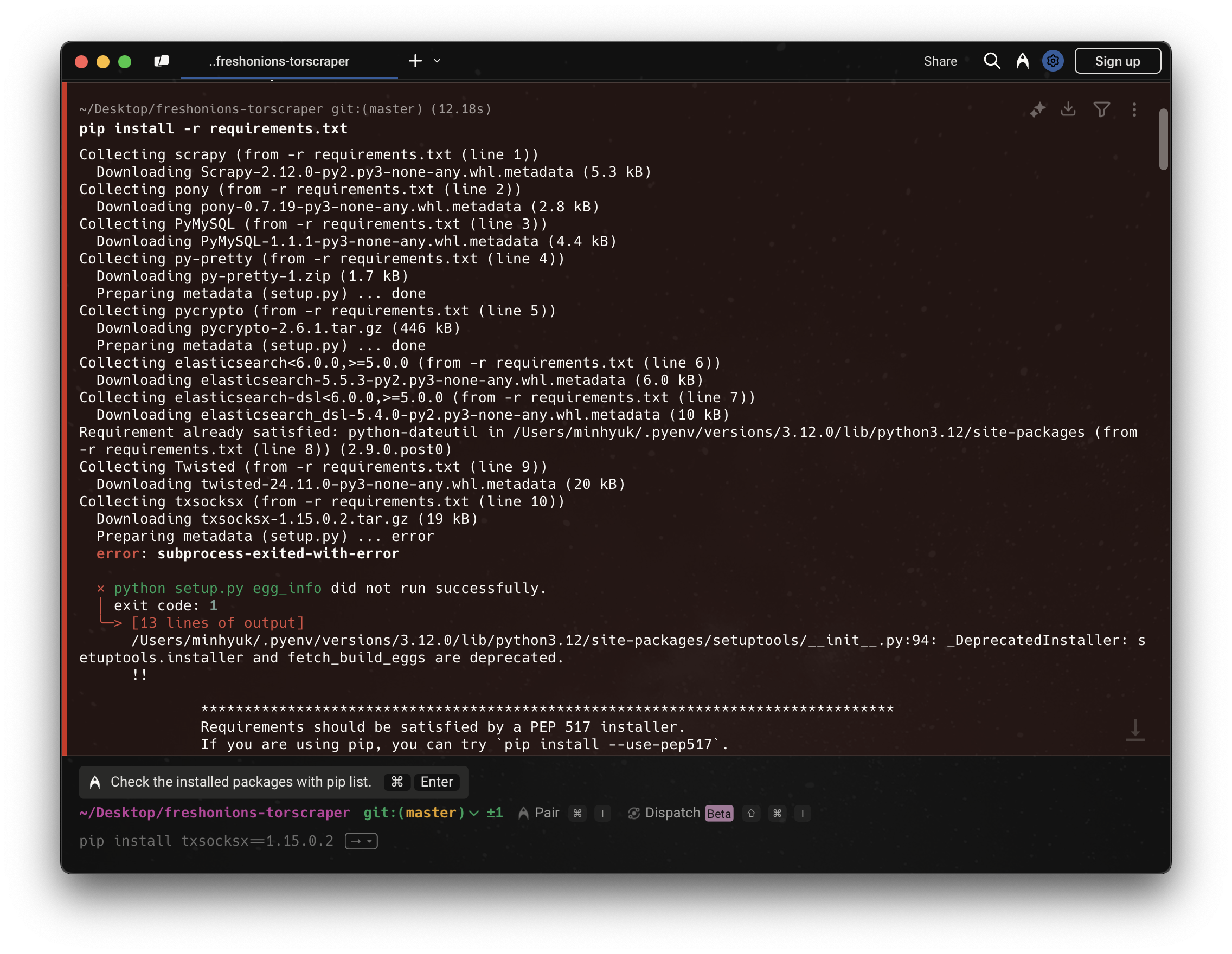
requirements.txt에 포함된 여러 패키지 중, txsocksx 패키지의 설치 중 metadata 생성 오류가 발생하여 전체 설치가 중단되었다.
txsocksx는 오래된 Twisted 기반의 SOCKS 프록시 지원 라이브러리로, 최근 pip/PEP517 빌드 시스템과 호환되지 않는 방식으로 setup.py가 작성되어 있다.
구체적으로는 install_requires 필드에 문자열이 아닌 int 타입이 들어가 있어서 pip가 의존성 목록을 파싱하지 못하고 오류를 발생시킨 것으로 보인다.
또한, 최신 PyPI에서 제공되는 버전은 1.15.0.2뿐이며, 이 버전도 동일한 문제를 가지고 있어 다른 버전으로 대체 설치할 수 없다.
따라서 txsocksx가 프로젝트에서 직접적으로 사용되지 않거나, 다른 패키지의 불필요한 의존성일 수 있기 때문에 requirements.txt에서 제거했다.
~ txsocksx
나머지 라이브러리를 정상적으로 설치
pip install --use-pep517 -r requirements.txt
 이어지는 설치 과정은 조금 까다로운 것 같다.
이어지는 설치 과정은 조금 까다로운 것 같다.
MySQL DB 생성
먼저 schema.sql 파일을 기반으로 MySQL에 DB를 생성해야 한다.
mysql -u root
# 로그인 후
CREATE DATABASE torscraper;
USE torscraper;
SOURCE /path/to/schema.sql;
etc/database 설정 파일 수정
torscraper 프로젝트 디렉토리 안에 있는 etc/database 파일을 열어서 수정한다.
HOST=localhost
PORT=3306
USER=root
PASSWORD=your_password
DB=torscraper
etc/proxy 설정
PROXY_TYPE=socks5h
PROXY_ADDR=127.0.0.1
PROXY_PORT=9050
.onion사이트 등록
실험 목적의 합법적인 onion 주소만 입력한다.
script/push.sh someoniondirectory.onion
script/push.sh anotheroniondirectory.onion
Python 2 문법이 Python 3에서 오류를 일으켰다.
다음과 같이 이전 문법을 사용하는 파일을 찾아서,
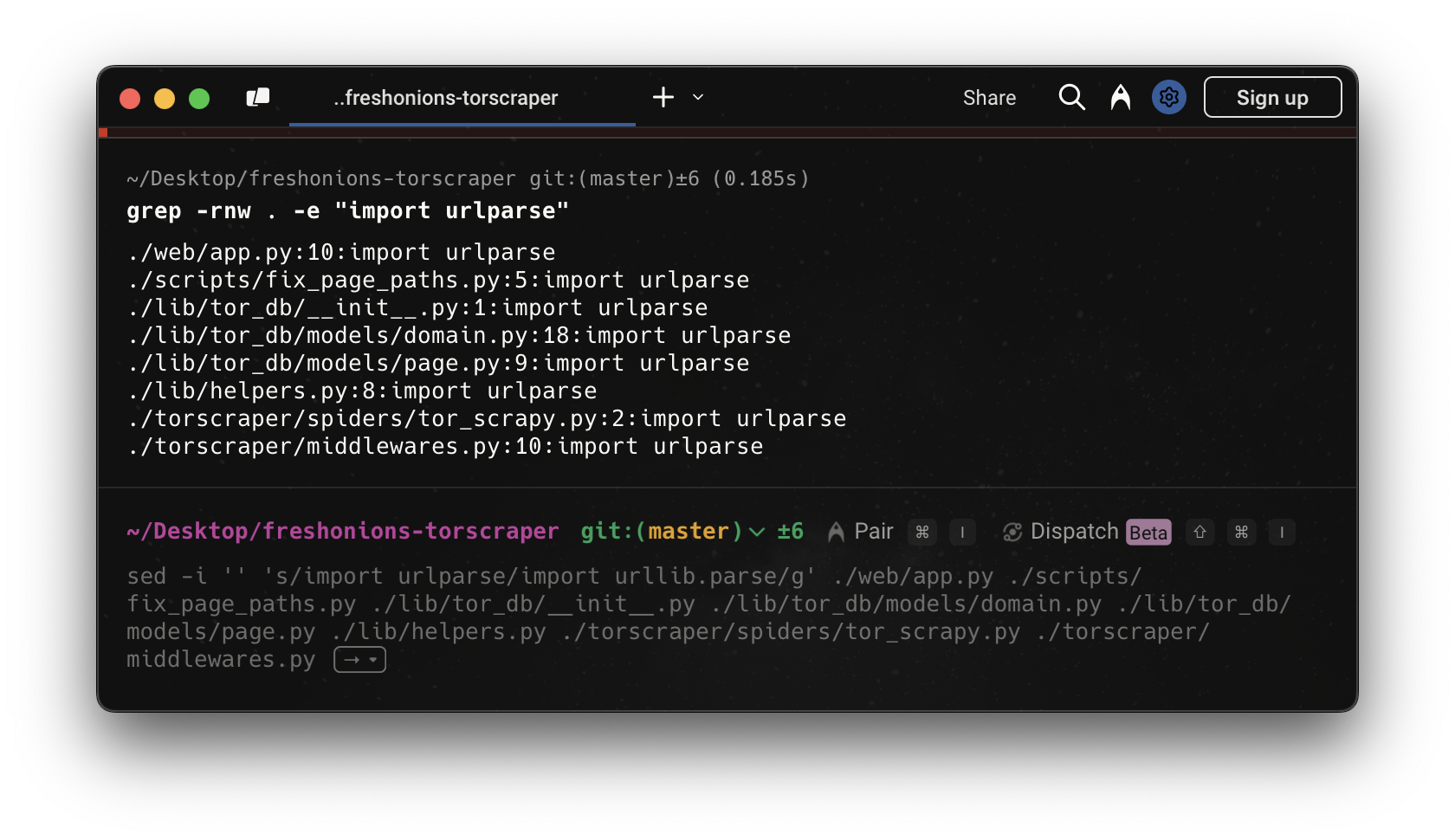 다음과 같이 수정해준다.
다음과 같이 수정해준다.
import urlparser -> from urllib import parser
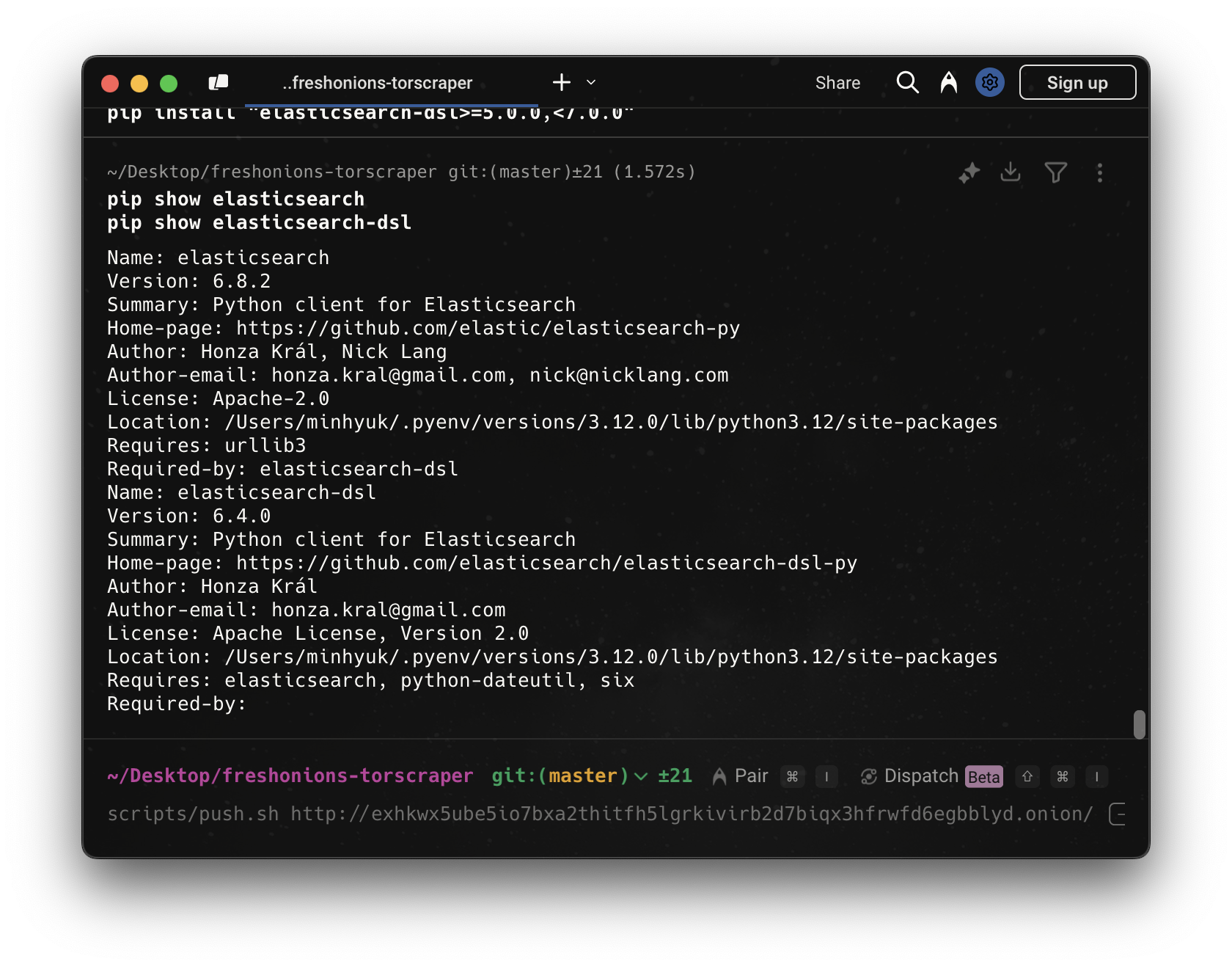
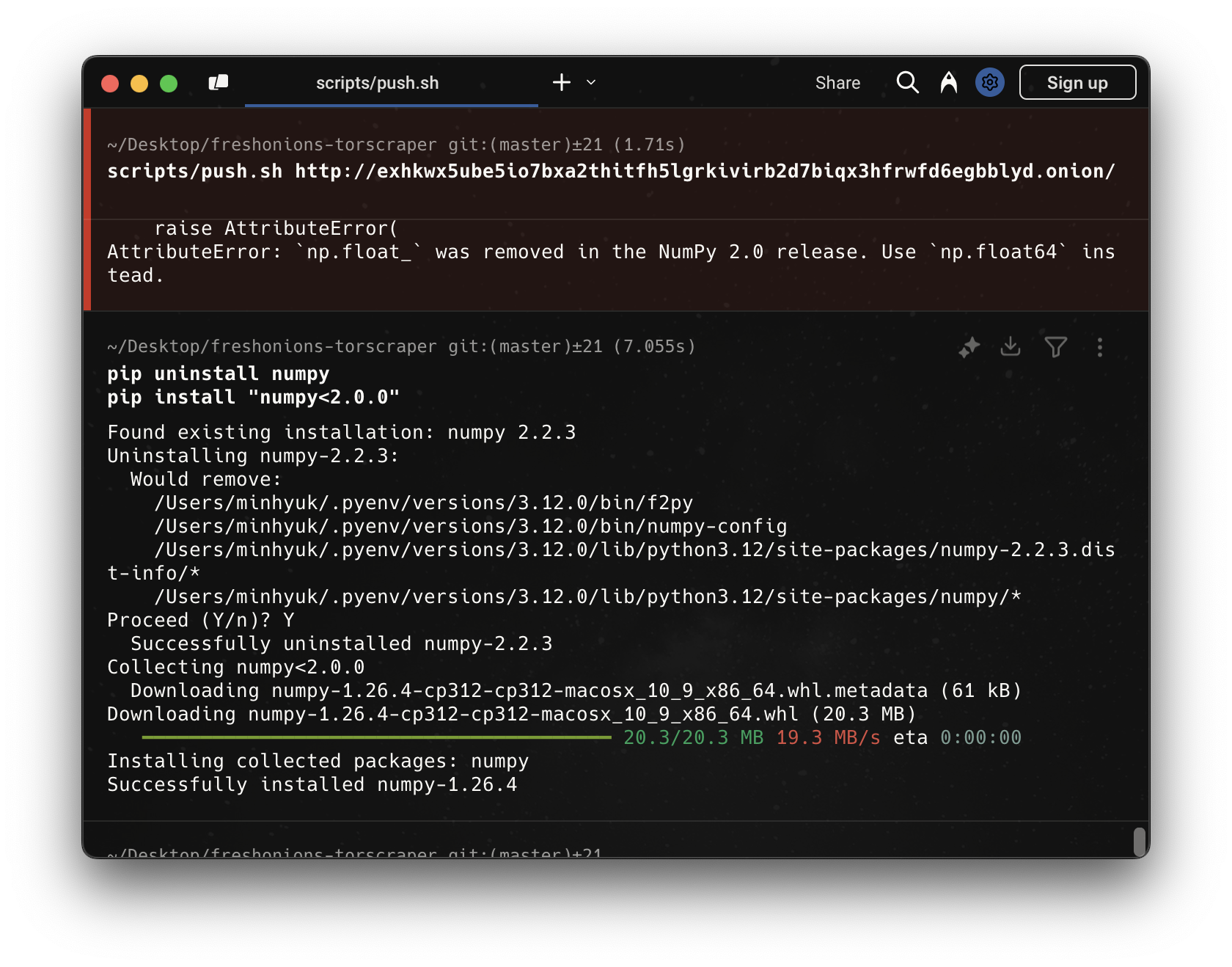
엘라스틱서치와 넘파이 버전 호환 문제와 해결해준다. 뭔가 점점 일이 커져가고 있다는 걸 실감했다.
결론
Torscraper는 최신 환경(Python3 + 최신 패키지)과 호환되지 않는다.
주요 실패 원인 요약
- Python 버전 문제
- Torscraper는 Python 2 또는 Python 3.6~3.8 기준으로 작성됨
- Python 3.12에서는 많은 문법·모듈 비호환 발생
- 패키지 충돌
- elasticsearch-dsl의 DocType, InnerObjectWrapper 등이 제거되었다.
- 최신 NumPy(2.x)는
np.float_제거로 elasticsearch와 충돌.- 의존성 난이도
- Scrapy, Elasticsearch DSL, NumPy, PyCrypto 등 오래된 라이브러리와의 충돌이 반복된다.
- 최신 환경에 맞춰 전면 refactoring 없이는 실행이 불가하다.
pyenv로 Python 3.6 환경을 구축해서 완전히 고립된 가상 환경에서 작동을 시켜보는 시도가 필요할 것 같다.
Onioff
설치
실행
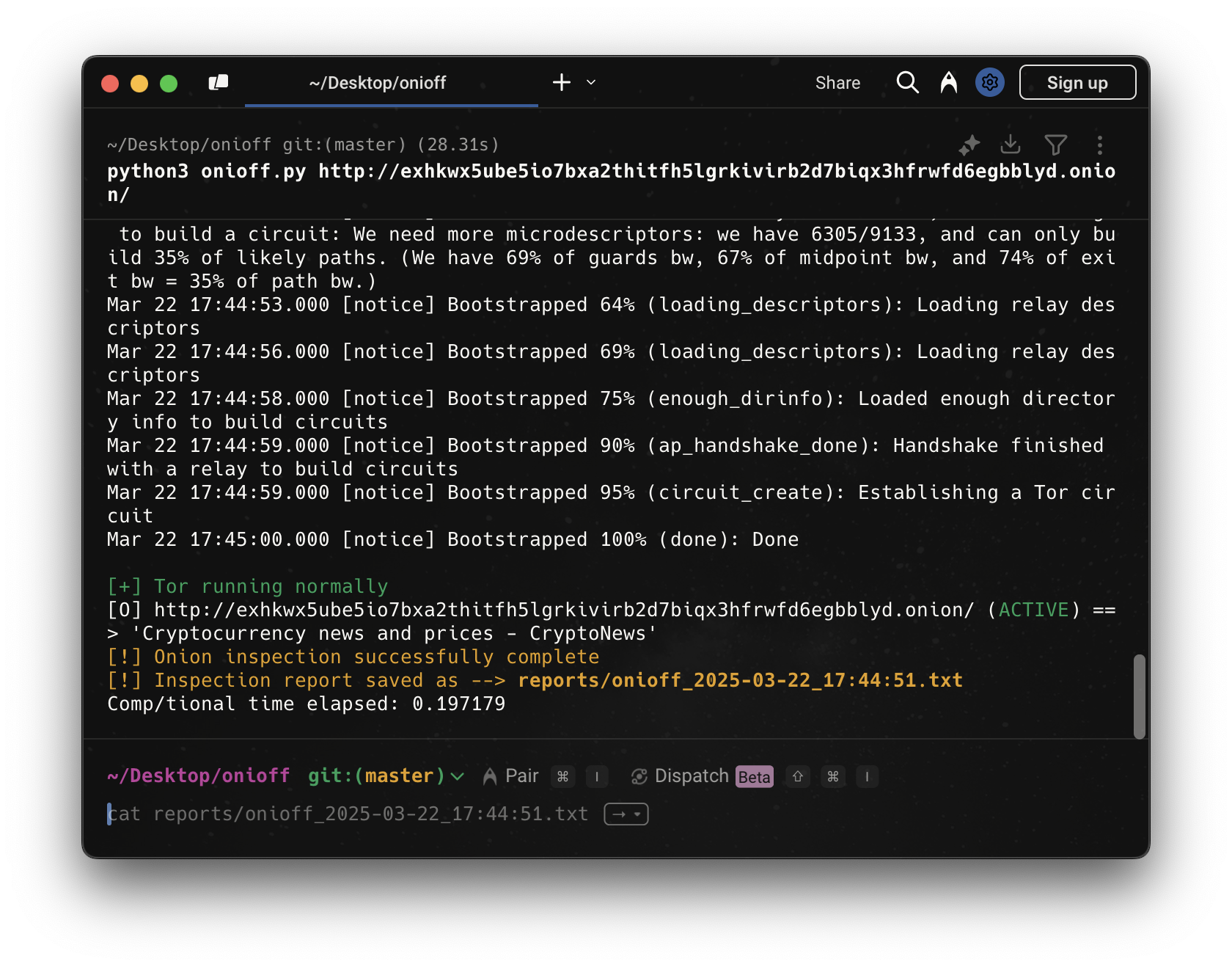 완벽히 작동했다. Tor 연결이 정상적으로 이루어졌고, Onioff가
완벽히 작동했다. Tor 연결이 정상적으로 이루어졌고, Onioff가 .onion 사이트 상태를 확인한 후 성공적으로 보고서를 저장했다.
이를 기반으로 .onion 탐지를 자동화하거나, 보고서를 파싱해서 DB에 넣는 방향도 추가적으로 고려해 볼 수 있을 것 같다.
TorCrawl
설치
Dependency를 설치해준다.
실행
python torcrawl.py -u http://exhkwx5ube5io7bxa2thitfh5lgrkivirb2d7biqx3hfrwfd6egbblyd.onion/
출력 결과는 다음과 같다.
- b’… ← 이건 Python이 바이트 문자열(bytes) 형태로 HTML을 출력한 것
- 실제 내용은 사이트의
<html>과</html>에 전체 문서가 포함되어 있다. - 제목 Cryptocurrency news and prices - CryptoNews도 정상적으로 파싱되었다.
- CSS, 이미지 링크, 내비게이션 바 등도 모두 포함되었다.
이후에 할 수 있는 행위를 생각해보면, 바이트 문자열을 일반 문자열로 디코딩하는 것이다. 현재는 b'...' 형태로 나오기 때문에 출력 코드를 아래처럼 바꾸면 더 읽기 좋을 것 같다.
print(response.content.decode('utf-8'))
또한, 특정 정보만을 추출 자동화할 수도 있다. 예를 들어 BeautifulSoup로 HTML에서 <title>이나 내부 링크만 추출할 수도 있다. 그리고 CSV나 TXT로 리스트를 만들어두고, 반복을 돌려 여러 .onion에 대해 반복 실행도 가능하다. 이로써 여러 사이트의 상태를 체크하며 정보 수집 자동화가 가능할 것으로 보인다.